 |
|
 |
|
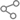

图说:“司南”大语言模型中英双语客观评测前十名 采访对象供图
新民晚报讯(记者 郜阳)大模型技术哪家强?30日,上海人工智能实验室科学家团队正式发布大模型开源开放评测体系“司南”(OpenCompass2.0),可以为大语言模型、多模态模型等提供一站式评测服务。
据介绍,“司南”全面量化模型在知识、语言、理解、推理和考试等五大能力维度的表现,评测榜单涉及的大语言模型和多模态大模型超过150个,客观中立地为大模型技术的创新提供坚实的技术支撑。截至目前,已有包括Meta、阿里巴巴、腾讯、百度等30余家国内外企业和科研机构采用“司南”助力开展技术研发。
同日,还揭晓了年度大模型评测榜单,对过去一年来主流大模型进行全面评测诊断。分析结果显示,GPT-4 Turbo在各项评测中均获最佳表现,国内厂商近期发布的模型紧随其后,包括智谱清言GLM-4、阿里巴巴Qwen-Max、百度文心一言4.0都获得不错的成绩。
记者了解到,基于全新升级的能力体系和工具链,“司南”构造了一套高质量的中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等多个方面。通过高质量、多层次的综合性能力评测基准,“司南”创新了多项能力评测方法,实现了对模型真实能力的全面诊断。
总体而言,大语言模型整体能力仍有较大提升空间;复杂推理相关能力仍旧是大模型普遍面临的难题,国内大模型相比于GPT-4还存在差距;中文场景下国内最新的大模型已展现出独特优势,在部分维度上接近GPT-4 Turbo的水平;此外,开源模型进步很快,以较小的体量达到较高性能水平,表现出较大的发展潜力。
上海人工智能实验室领军科学家林达华表示,对大模型“打分”要做到客观公允、方式科学、维度全面,“对模型的能力评测不仅是技术进步的度量衡,更是推动模型迭代和优化的重要驱动力。”
另据介绍,基于“司南”大模型评测体系,司南大模型评测伙伴计划正式启动。未来,“司南”将与各行业的头部企业机构一起,构建各类高质量行业评测基准,致力于推进大模型在千行百业应用落地和实践。
新民报系成员|客户端|官方微博|微信矩阵|新民网|广告刊例|战略合作伙伴
北大方正|上海音乐厅|中卫普信|今日头条|钱报网|中国网信网|中国禁毒网|人民日报中央厨房
增值电信业务经营许可证(ICP):沪B2-20110022号|互联网新闻信息服务许可证:31120170003|信息网络传播视听节目许可证:0909381
广电节目制作经营许可证:(沪)字第536号|违法与不良信息举报电话15900430043|跟帖评论自律管理承诺书
 |沪公网安备 31010602000044号|沪公网安备 31010602000590号|沪公网安备 31010602000579号
|沪公网安备 31010602000044号|沪公网安备 31010602000590号|沪公网安备 31010602000579号
新民晚报官方网站 xinmin.cn ©2024 All rights reserved



